AV Blog 1: ML Ops for Solo Research

Documenting my process as an independent researcher building toward end-to-end autonomous driving from natural video — hardware, compute, data, and early goals.
I have an ongoing obsession with computer vision for autonomous vehicles. I am starting this blog to document my process as an independent researcher catching up with the computer vision research which will (hopefully) be the future of driving.
Independent research is hard — it requires motivation, clear goals, and adaptation to unexpected challenges. In this first blog I’ll discuss what I’ve learned about my technology stack from early experiments.
Part 1: Overview
To participate in deep learning research, there is a fairly large hardware and software boundary to overcome. We need data storage, GPU compute, data, and research direction. With the price of a cutting-edge GPU around $30,000, I knew I would have to get familiar with cloud computing quickly.
Eventually, I settled on the following workload, with the following requirements for my overall research environment:
- Easy for a non-technical (from a computer networking perspective…) AI researcher to get started.
- Low cost, low commitment.
- Hosting ~200GB of training data in persistent storage.
- Reproducibility of experiments and research efforts.
In solo research, a simple (cheap) workflow speeds up research iterations.
Figure 1: Vast.ai gives at-a-glance pricing breakdown of rates, TFLOPS/$/hr, and storage.
Part 2: Compute
GPU compute is the bottleneck for all deep learning research. It is hard to avoid training or fine-tuning models during most research efforts. Finding a cloud compute provider for a non-expert was the first challenge in my workflow. I’ve tried to use AWS before and found it extremely overwhelming. A one-click solution with reasonable prices was my goal, which I found with vast.ai (sponsor me?). I also needed reasonable storage cost since I was interested in model training, not just inference hosting.
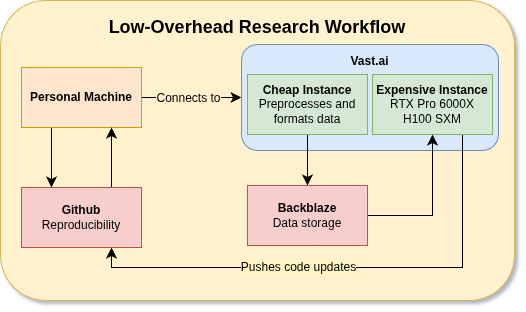
Figure 2: Design of my ease-to-use research environment.
I found vast.ai to have a huge supply of available machines, low prices, and reasonable storage rates for training data. With no commitment!
Part 3: Process
Figure 3: Cheap instance hosts data and does some background work. “Expensive” instance is the torch compute.
I use a cheap-instance / expensive-instance setup. So far, my workflow has been:
- Using a cheap instance to download Bench2Drive, extract the data, resize the images and segmentation masks, and delete unwanted annotations.
- Vibe-code some preliminary models (discussed in Blog 2) and draft up a file system and workflow. Push the code to our repo.
- Re-compress the data and upload to Backblaze for storage and cloud-syncing.
- Pull the data on the “expensive” machine. Pull the code.
- Start training on the expensive machine. Push changes as we implement new models, features.
Part 4: Goals
I want to build towards E2E (end-to-end) driving of autonomous vehicles using natural video. This means no expensive LiDAR hardware — just some cameras strapped to a car. To do this, I’m starting from what I know: some basics in estimating depth, semantic segmentation, and instance segmentation from streaming video.
Recent work foregoes this step of feature extraction and directly predicts mapping, detection, prediction, and planning from sensor data. This is fascinating, but I want to build towards it with building blocks.
The research process will start from experiments and proposing some fast feature extraction from streaming video which may benefit downstream E2E models. Future work will set up an E2E research environment to try new ideas.
Here’s a teaser for some of the work I’ve done so far — discussed in the next post:

Figure 4: Teaser for next post on depth+segmentation estimation from multicamera video.
Follow along with the code:
