AV Blog 2: Feature Extraction from Multi-Camera Video

Exploring the Bench2Drive dataset and drafting architectures for simultaneous depth and semantic segmentation from multicamera streaming video.
Before we get to E2E driving, let’s explore the Bench2Drive data and draft some architectures for multimodal feature extraction from multicamera streaming video!
Chapter 1: The Task
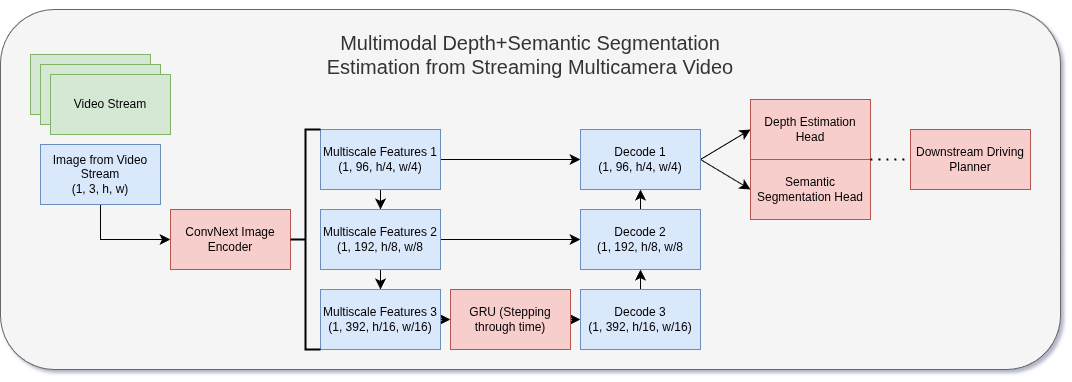
I am looking to simultaneously predict the depth and semantic segmentation of 6 onboard cameras in the Bench2Drive dataset. I’m using a fixed resolution of (450, 800) — half the height and width of the usual dataset.
I’ve gravitated towards depth and semantic segmentation as useful features to extract for E2E driving. My hypothesis is that depth alone gives us a field to navigate with potential obstacles, but using semantic segmentation also gives us the class of those obstacles. Buildings move differently than cars, after all!
Another derived feature would be an intersection of the semantic segmentation and depth field. In my mind, these are a pseudo-3D bounding box: we process the incoming video stream into a discrete set of objects where we predict their class and distance from ego. We do sacrifice orientation in this case, however.
We have tensors at training time of size (batch_size, 6_cameras, t_frames, 3_rgb, h, w). For baselines, we broadcast an image-based model over both time and cameras: (bs*6*t, 3, h, w). Future models can explore the benefits of temporal information via windowed approaches to local time, or multi-camera approaches for object permanence and ego positioning through additional frame context.
Chapter 2: The Approach(es)
We have quite a few architectures to explore for this task. I always gravitate towards a U-Net style architecture when the model target has the same spatial structure as the input — which is the case for both depth and segmentation.
I introduce a few baselines to get started:
- Depth-only and segmentation-only training runs using a convolutional U-Net, for baseline performance metrics.
- A multimodal model combining both heads, with different encoder sizes (ResNet-18/34/50/101/152) to explore scaling behavior.
- A temporal model using an RNN over frame latents at the bottleneck of the U-Net, bringing in temporal context as we iterate through video.
Chapter 3: Results and Metrics

Losses
Semantic Segmentation: Cross-entropy loss, Dice Loss, or Focal Loss. Stated as a classification problem on all pixels of a scene belonging to one of 23 Bench2Drive classes (Road, Car, Tree, Sky, Lamp Post, …). Dice and Focal losses address the class imbalance problem — 99% of our scenes are roads, buildings, sky, and cars, yet small classes like traffic lights and road obstacles are vital.
Depth Estimation: SiLog (scale-invariant logarithmic) loss. Scale-invariance means we return a relative depth field where the estimated distance between pixels is measured rather than absolute distance from camera. Methods such as stereo vision and Structure from Motion can estimate absolute depth more accurately.
Metrics
Semantic Segmentation: Accuracy, per-class DICE, weighted IoU. Weighted metrics assign higher weight to low-count classes which are not less important to detect.
Depth Estimation: Absolute Relative Error (AbsRel). AbsRel expresses the difference between predicted and ground truth depth as a percentage of magnitude — making it scale-invariant.
Chapter 4: The Sim-to-Real Gap

Real-world video perception introduces countless new challenges which simulation fails to capture. Real-world video streams are often occluded, foggy, dirty, compressed, corrupted, and blurry.
There are a few experiments worth exploring to close this simulation-to-reality gap, which plagues deployed computer vision systems and is omnipresent in robotics.
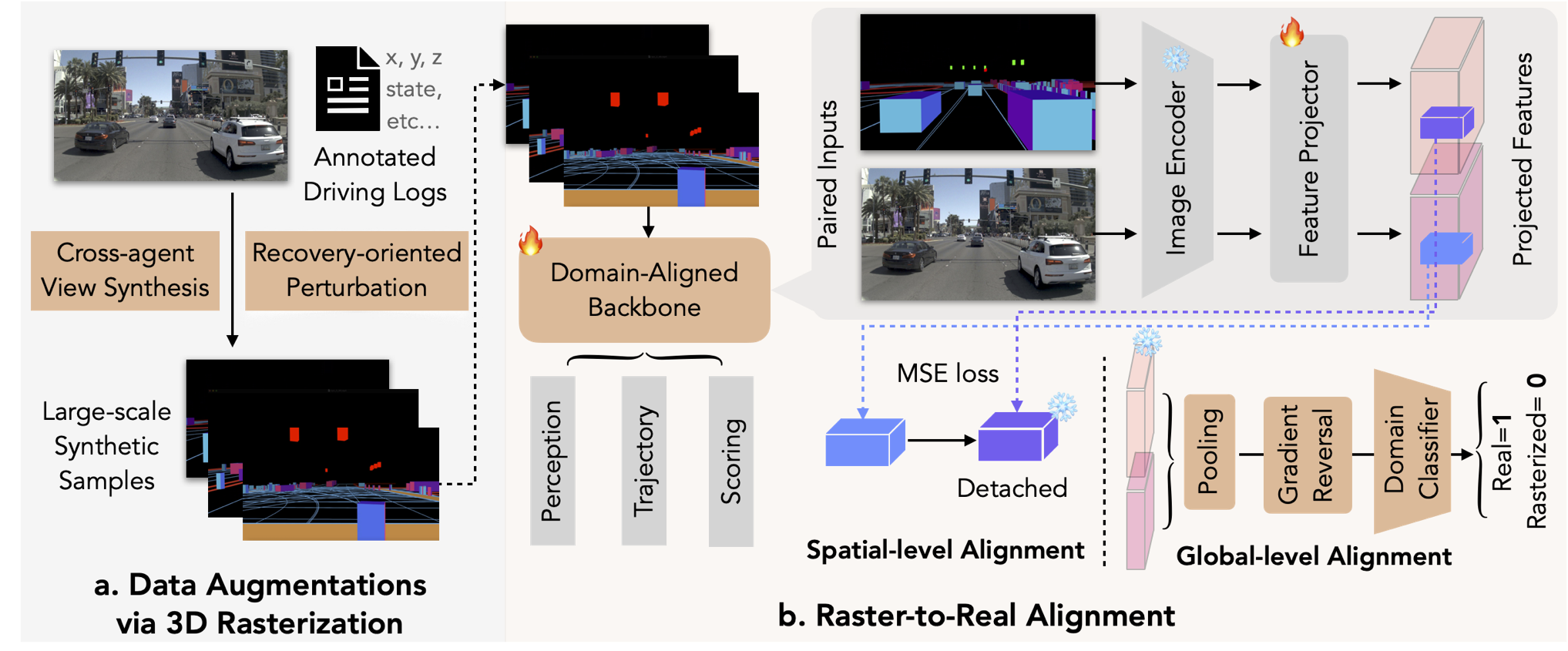
RAP 3D argues that autonomous driving is not about simulating the most realistic graphics in which to train models, but that driving is about 3D perception, object motion, and environmental understanding — not high-fidelity graphics. They produce a highly-scalable synthetic data production engine with low-resolution graphics which mirrors the latent structure of real-world video under their custom vision encoder.