AV Blog 9: Paper Review: Recurrent Video Masked Autoencoders
Reviewing Recurrent Video Masked Autoencoders (and perception4d).
(Note: This post was produced WITHOUT LLMs)
| GitHub | ArXiv |
Caption: Considering both dense spatial and captioning tasks, RVM outperforms general video encoders.
Chapter 1: Background
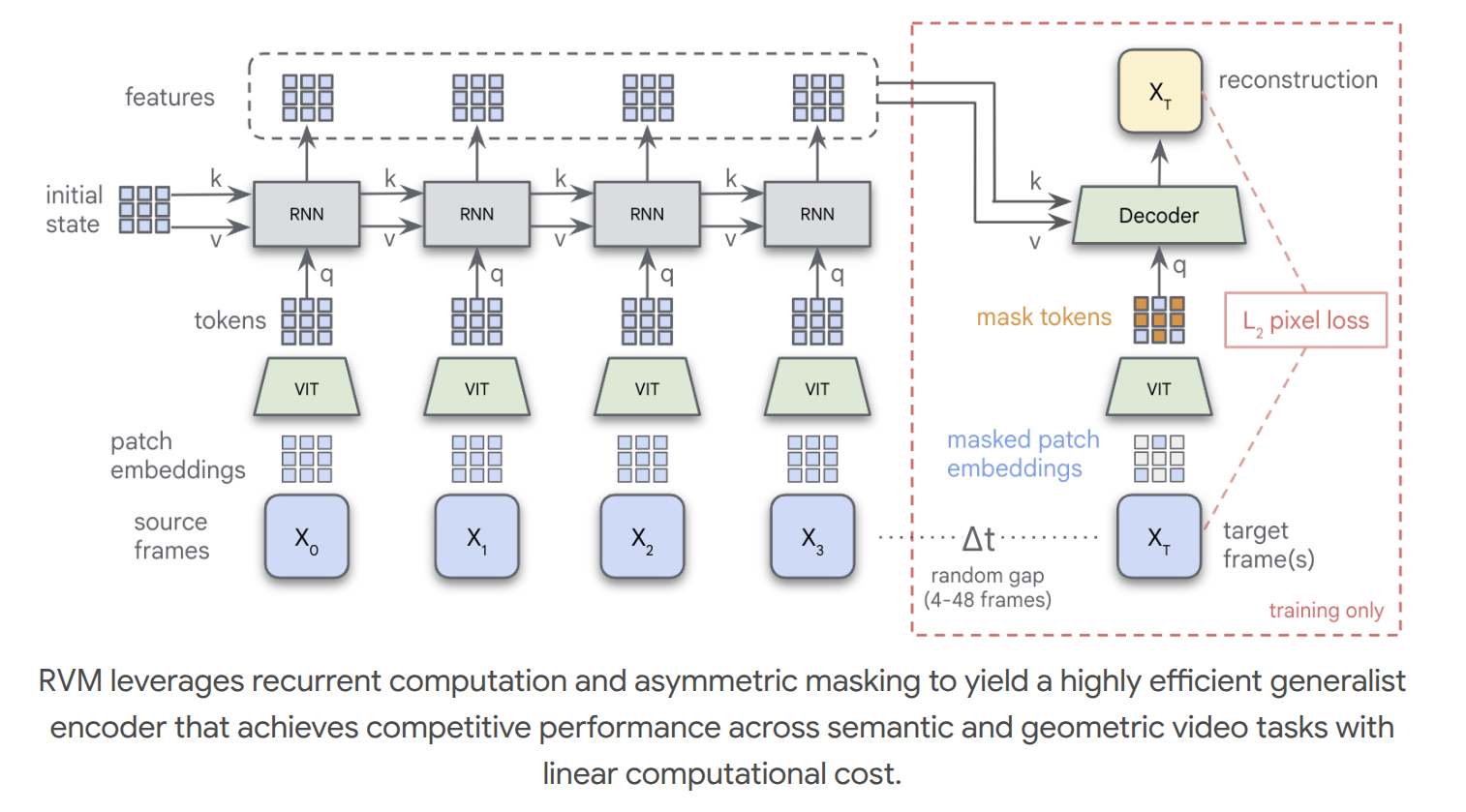
Recurrent Video Masked Autoencoders (RVM) are a novel approach to video representation learning using recurrent transformers to aggregate dense features over time. RVM lears via asymmetric masked prediction using pixel reconstruction. RVM achieves generalist performance against state-of-the-art video encoders (VideoMAE, V-JEPA). Like the EUPE paper, this holds against various downstream video-level tasks like point and object tracking, geomtric, and dense spatial understanding. Up to 30x greater parameter efficiency than competing video masked autoencoders. Features are stably propegated over long temporal horizons despite linear complexity cost, overcoming standard limitations of RNNs AND attention-based architectures. RVM learns rich representations in scene semantics, structure, and motion.
This paper comes from a long line of video representation models which model the world by predicting the spatio-temporal evolution of the world as self-supervised learning.
JEPAs (Joint Embedding Predictive Architectures) predict future states in latent space. VideoMAE and V-JEPA rely on early-fusion spatio-temporal encoders (with spatiotemporal attention throughout the network) and random masking across entire clips. This treats time as uniform and symmetric, both in masking and in attention, neglecting the casual nature of temporal dynamics. This limits their application to streaming video such as robotics. Chunked offline representations also prevent consistent representations over long time horizons.
DINO family are capable of learning stable semantic features unrolled over multiple frames, but fail to encode motion information in features.
RVM addresses these shortcomings by explicitly modeling asymetry through timne in both maskiing adn architecture. Videos are processed sequentially by aggregating frame-level representations. These representations genralize to spatial and video (spatio-temporal) tasks. This recurrent design has emergent stability over long time horizons, and unrolls over sequences with linear compute AND memory!
Related Work Self-supervised video. Learns from unlabeled mass video. Contrastive or reconstructive approaches.
Mask Autoencoders. Lots of work in Siamese networks, masked reconstruction.
Recurrent Video models. (For me, the most interesting section). These approaches do NOT use windows of frames for offline inference and therfore can be applied in real-time to streaming video. RViT recurrent vision transformer [77] and RCNN recurrent convolutional networks learns spatio-temporal video in recurrent connections in its layers. State space models such as VideoMamba and VideoMambaPro also do linear video understanding. However these rely on non-causal, bi-directional learning! They also consider videos as flat token sequences - losing spatial info.
Chapter 2: Method
Approach:
Sequence of t frames is encoded under ViT with 2d position encoding. We iterate with an RNN, where k,v come from an initial state. The initial state and ViT output tokens are input to RNN, which returns state St. k,v are then propegated to next RNN input along with next frame tokens.
Chapter 3: Experiments
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Vestibulum ante ipsum primis in faucibus orci luctus et ultrices posuere cubilia curae; Proin vel ante a orci tempus eleifend ut et magna. They evaluate on three standard benchmarks: [Benchmark A], [Benchmark B], and nuScenes detection.
| Model | [Metric A] ↑ | [Metric B] ↑ | Latency (ms) | Params |
|---|---|---|---|---|
| [Baseline 1] | 52.3 | 41.7 | 48 | 86M |
| [Baseline 2] | 55.1 | 44.2 | 63 | 120M |
| [This Paper] | 58.9 | 47.6 | 31 | 72M |
The proposed model achieves state-of-the-art on both metrics at roughly half the latency of [Baseline 2], despite fewer parameters. The gains on [Metric B] are especially notable — [to be filled in].
![[Placeholder: Results chart — metric vs latency tradeoff]](/images/placeholder_results_chart.png)
Chapter 4: Ablations
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Fusce et ipsum vitae ipsum tristique lobortis id vitae nunc.
| Ablation | [Metric A] | Notes |
|---|---|---|
| Full model | 58.9 | — |
| w/o cross-modal attention | 55.4 | −3.5 pts |
| w/o [Module 2] | 56.1 | −2.8 pts |
| Camera-only | 49.7 | −9.2 pts |
| LiDAR-only | 51.3 | −7.6 pts |
The ablation confirms that cross-modal attention is the single largest contributor to performance. Removing [Module 2] also hurts, though less severely. Neither modality alone approaches the fused result, which is expected but good to verify empirically.
Research note: [To be filled in — any surprising ablation results worth calling out?]
Chapter 5: How It Fits into the E2E Stack
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Praesent dapibus, neque id cursus faucibus, tortor neque egestas augue, eu vulputate magna eros eu erat. A universal encoder that produces a single token sequence is a natural fit upstream of an E2E planner — the planner can treat perception as a black box and just consume tokens, regardless of sensor configuration.
The key open questions for integrating this into our pipeline:
- Temporal context: Does the encoder produce per-frame tokens, or does it incorporate a temporal window? If per-frame, we’d need to add a temporal aggregation step (similar to what we’re already doing with VideoMAE).
- Resolution compatibility: Our current setup uses 224×224 camera inputs. If the encoder’s tokenizer expects a different resolution, we’d need to adapt it.
- Downstream task heads: The paper evaluates detection and segmentation heads. A planning head is straightforward to add in principle — worth trying against our existing trajectory prediction baseline.
![[Placeholder: Integration diagram for E2E pipeline]](/images/placeholder_integration.png)
Chapter 6: What’s Next
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Sed lacinia, urna non tincidunt mattis, tortor neque adipiscing diam, a cursus ipsum ante quis turpis. A few directions worth exploring:
- Swap the backbone in our RAP setup: RAP currently uses DINOv3-H as its vision encoder. It would be straightforward to substitute the universal encoder here and re-run the NAVSIM benchmark — clean apples-to-apples comparison.
- Distillation into a lightweight variant: The full model is 72M params, which is reasonable but not edge-friendly. TinyViT-style distillation from this encoder into a smaller student could be worth doing.
- Cross-benchmark evaluation: The paper focuses on [Benchmark A/B]. Worth checking how the encoder holds up on Bench2Drive’s closed-loop eval, where sensor noise and distribution shift matter more.
Don’t take my word for it — read their work.
Feature Visualisations
The frozen RVM-L16 encoder produces rich spatial-temporal representations without any task-specific training. Below we visualise the patch-level hidden state across three different video sources: DAVIS (natural scenes), CARLA/Bench2Drive (synthetic driving), and Perception Test (in-the-wild).
Each strip shows: original · PCA features (first 3 principal components as RGB) · K-means (k=8) unsupervised clusters · state change (cosine distance from frame 0, Turbo colourmap).
DAVIS — Natural Scenes
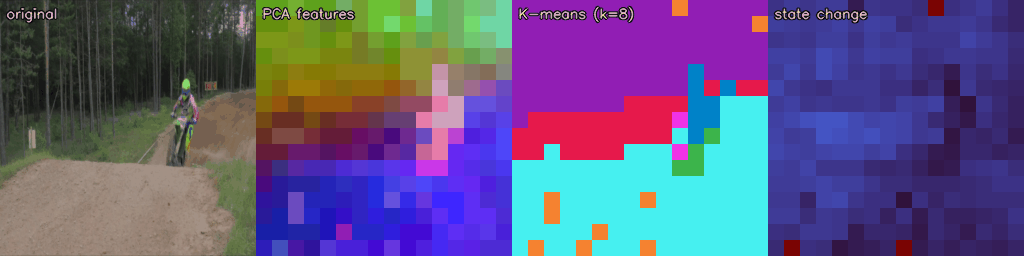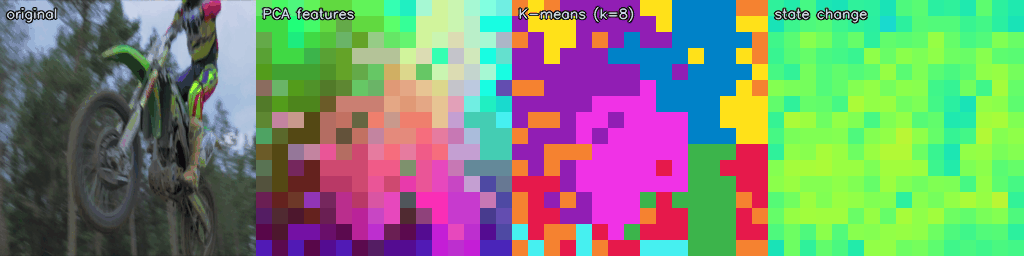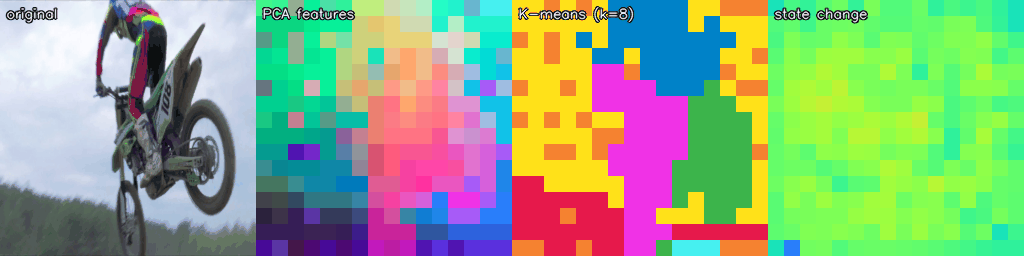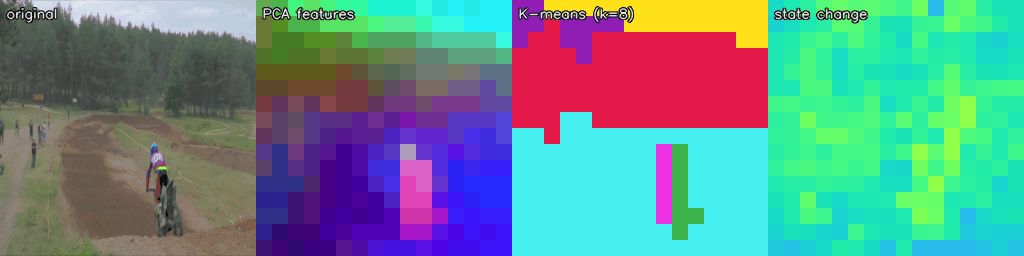






CARLA / Bench2Drive — Synthetic Driving
The encoder generalises to synthetic driving footage with no fine-tuning, cleanly segmenting road surface, vehicles, sky, and vegetation.



Perception Test — In-the-Wild Video



