AV Blog 4: End-to-End Trajectory Planning from Vision

Designing and ablating a suite of neural planners — from a pure-kinematics MLP baseline through vision-augmented transformer architectures with auxiliary depth supervision.
(Note: Sections of this post, and the architecture figures, were produced by LLMs)
With depth and segmentation extraction covered in the last post, it’s time to tackle the core problem: end-to-end trajectory planning. Given sensor history, where should the car go next?
This post introduces six model architectures of increasing complexity, and lays out the ablation study designed to understand which components of a vision-augmented planner actually matter.
Here’s a mid-training snapshot from TensorBoard:
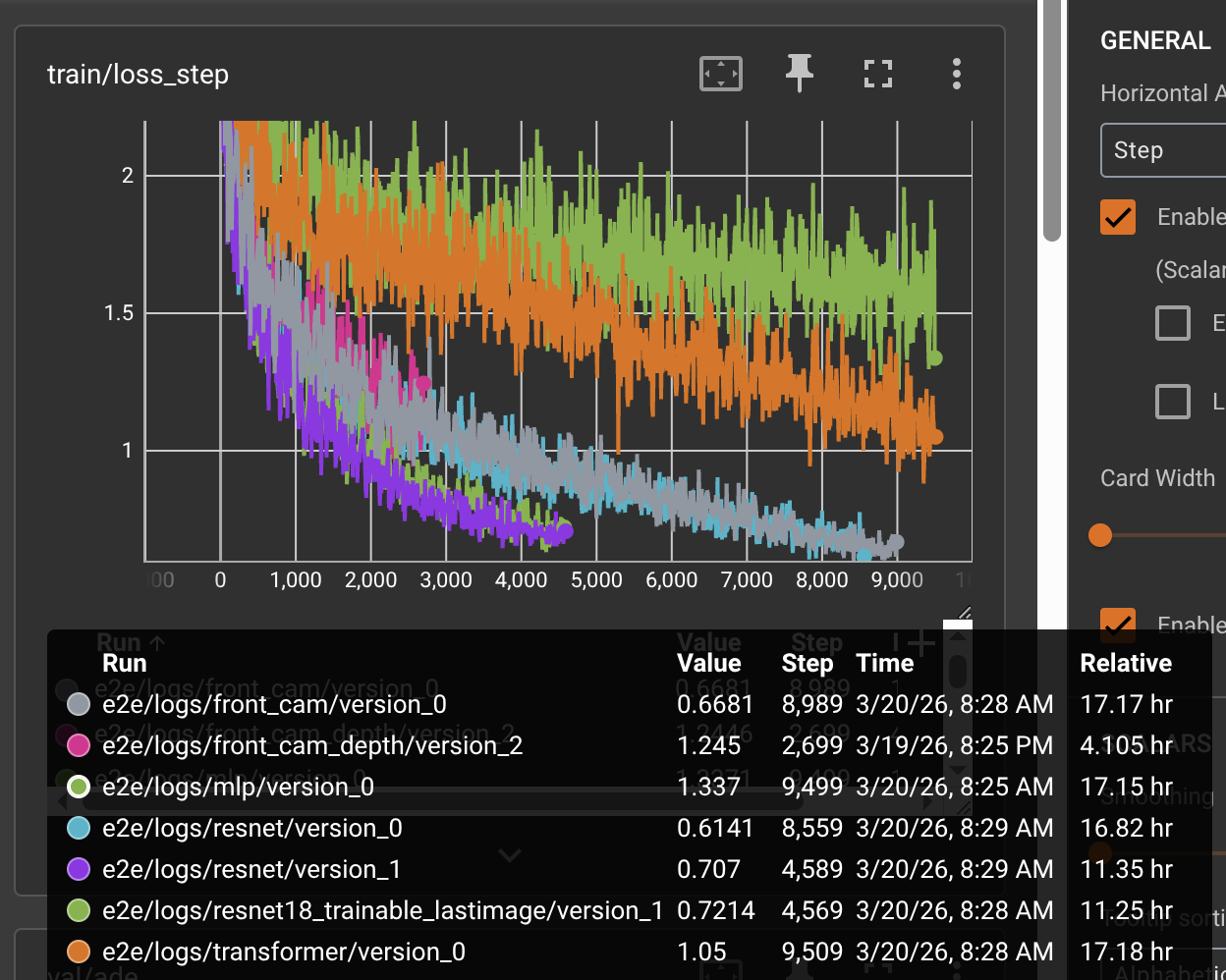
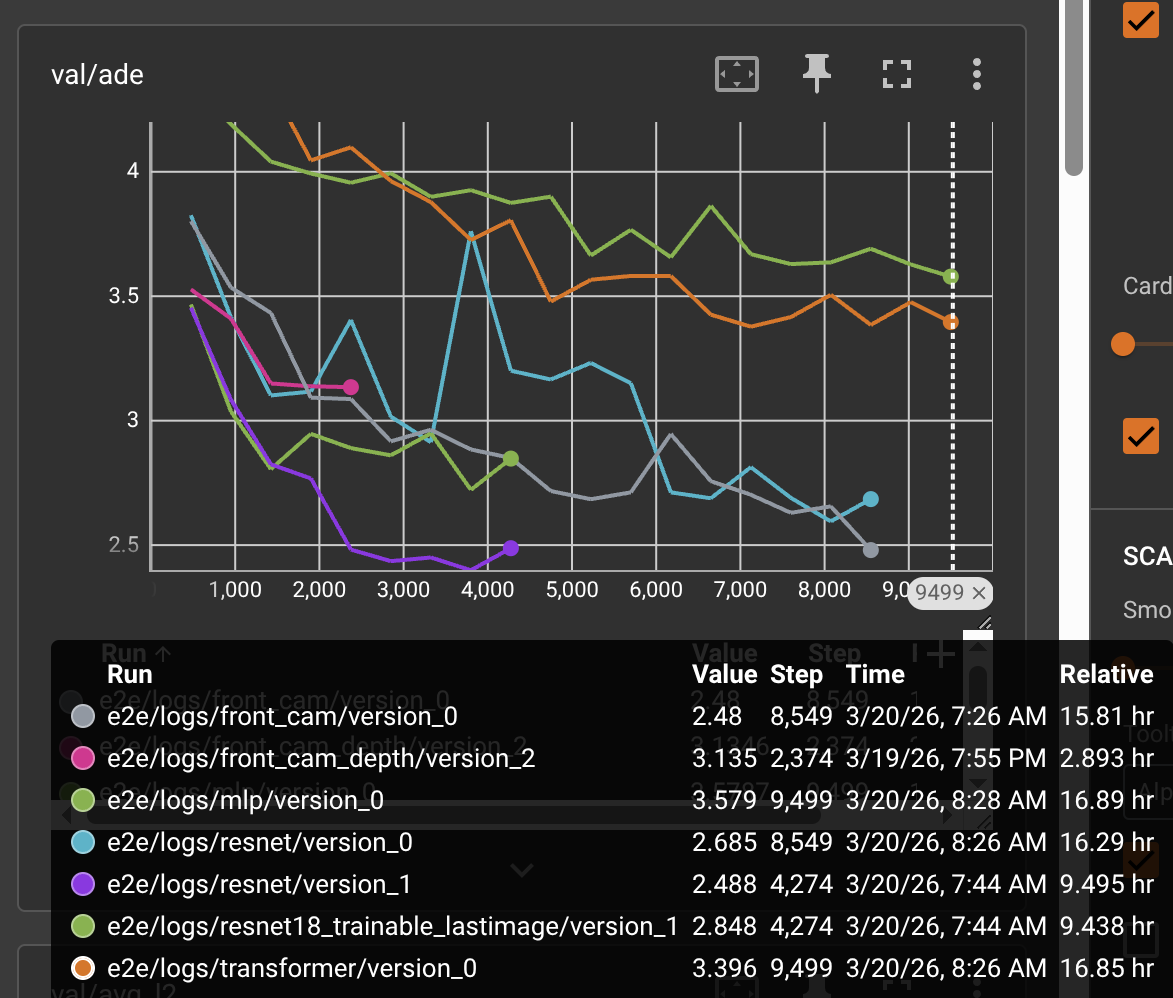
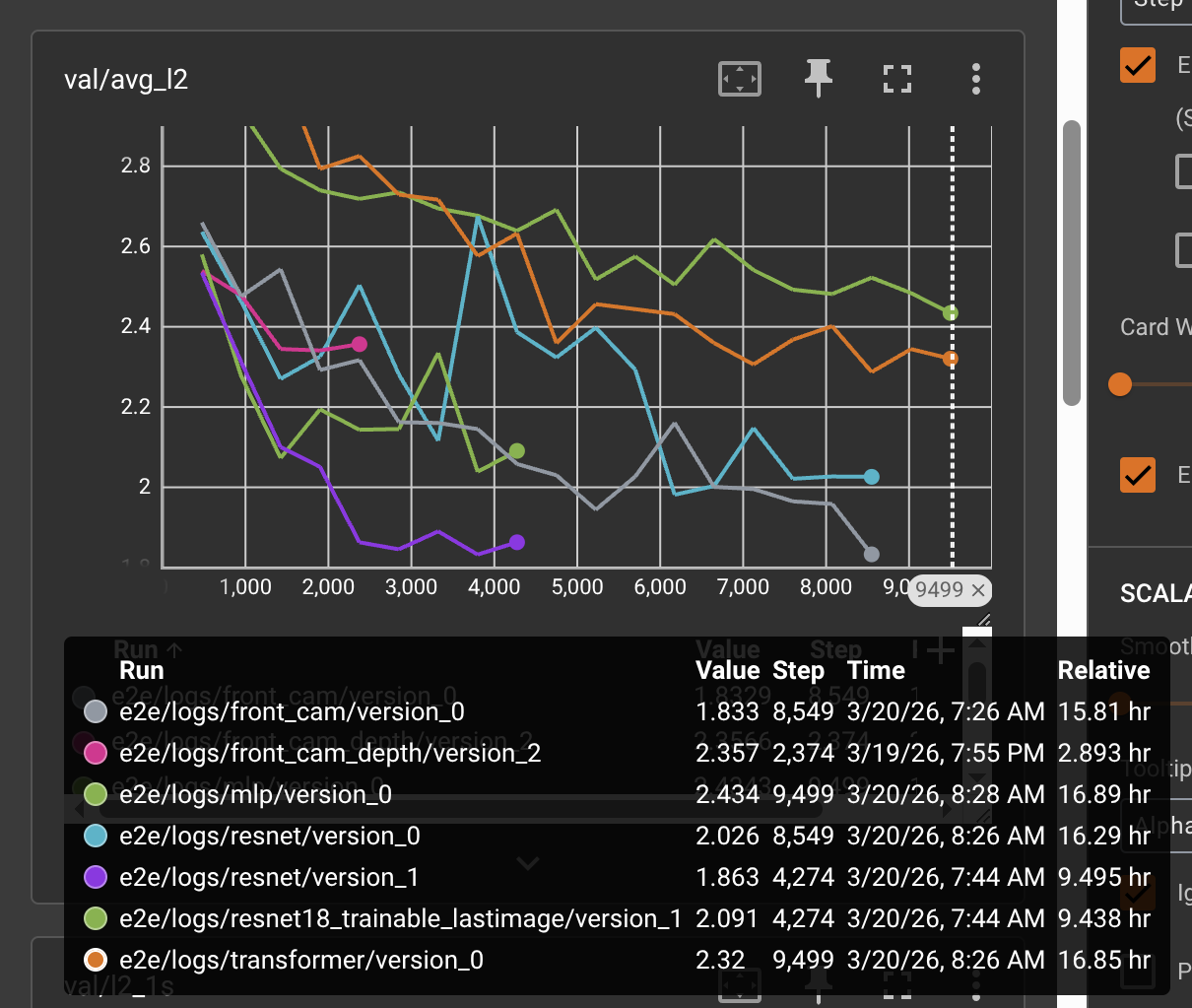
Chapter 1: The Task

The planner takes in a window of recent sensor data and must predict the next 50 future waypoints of the ego vehicle. Inputs available at each timestep:
| Input | Shape | Description |
|---|---|---|
past_traj | (B, 41, 2) | Last ~4s of ego (x, y) positions |
speed | (B, 41) | Ego speed per timestep |
acceleration | (B, 41, 3) | 3-axis acceleration per timestep |
command | (B,) | High-level driving command (turn left/right, go straight, follow lane) |
images | (B, C, 3, 224, 224) | Onboard camera frames — 1 (front) or 6 (surround) |
The planner outputs a future trajectory: (B, 50, 2) waypoints over the next ~5 seconds.
Why 41 past steps and 50 future steps? The Bench2Drive dataset runs at ~10Hz. 41 frames ≈ 4 seconds of history; 50 frames ≈ 5 seconds of future — long enough to capture a full lane change or intersection crossing.
Chapter 2: The Architectures
Six architectures are implemented, progressively adding components. Each builds intuition for what contributes to planning performance.
Architecture 1: MLP Planner
The simplest possible baseline. All kinematic inputs are flattened into a single vector and fed through a deep MLP.

Key design choices:
- Input: flatten
past_traj(82) +speed(41) +acceleration(123) + one-hotcommand(4) = 286-dim vector - 4× [Linear(256) → LayerNorm → GELU → Dropout(0.1)]
- Output: Linear(100) reshaped to (50, 2) waypoints
- Parameters: 289K
This model is vision-free. It asks: how well can we plan from kinematics alone? It also gives us a compute and accuracy floor for every subsequent architecture.
Architecture 2: Transformer Planner
The same kinematic inputs — but rather than flattening, we preserve the temporal structure of the 41-step history. Each timestep becomes a token; a transformer encoder learns temporal relationships, and a decoder with learned query embeddings generates the future trajectory.

Key design choices:
- Per-timestep token:
[x, y, speed, acc_x, acc_y, acc_z, cmd_0..3]= 10-dim - Input projection: Linear(10 → 128) + sinusoidal positional encoding
- 3× TransformerEncoderLayer (4 heads, FFN=512)
- 3× TransformerDecoderLayer with 50 learned query embeddings
- Output: Linear(128 → 2) per query
- Parameters: 1.4M
Ablation question: Does temporal attention over kinematics outperform the MLP’s flattened view?
Architecture 3: ResNet Planner
Now we add vision. The front camera is encoded with a frozen, pretrained ResNet50 backbone. Visual features are projected to token embeddings and fused with kinematic memory inside a cross-attention decoder.

Key design choices:
- Frozen ResNet50: no gradient flows into the backbone — visual features are treated as a fixed prior
- Supports single-scale (7×7 = 49 tokens from layer4) or multiscale (56²+28²+14²+7² = 4,410 tokens)
KinematicEncoder: 2-layer transformer encoder over the kinematic sequence-
FlexDecoderLayer: self-attention on future queries + cross-attention to [visual tokenskinematic tokens] - Parameters: 33.2M (dominated by frozen ResNet50 ~25M)
Ablation questions:
- Does vision from ResNet50 improve over kinematics-only?
- Does multiscale visual context (small objects at higher resolution) improve planning?
Architecture 4: Front Camera Planner
Swaps the ResNet50 backbone for a frozen TinyViT — a lightweight Vision Transformer that generates richer spatial tokens with less compute than a full ViT. Still limited to the single front camera.

Key design choices:
- Frozen TinyViT: produces richer semantic tokens than ResNet’s convolutional features
- 2D sinusoidal positional encodings for spatial awareness in the visual tokens
- Otherwise structurally identical to ResNetPlanner
- Parameters: 29.6M (dominated by frozen TinyViT ~28M)
Ablation question: Does TinyViT’s attention-based feature extraction improve over ResNet50’s convolution-based features for trajectory planning?
Architecture 5: Front Camera + Depth Planner
Adds an auxiliary depth estimation head to the Front Camera Planner. The hypothesis: training to predict depth forces the visual encoder tokens to encode geometry, which then benefits trajectory planning.

Key design choices:
- Trajectory decoder and depth decoder are separate (no shared weights beyond the backbone tokens)
- Depth head outputs
(B, 1, 224, 224)— a full-resolution depth map - Depth loss is only applied when depth ground truth is available (curriculum-friendly)
- At inference, only the trajectory head is used
- Parameters: 35.7M (+6.1M depth decoder over Front Cam Planner)
Ablation questions:
- Does geometric auxiliary supervision improve trajectory accuracy?
- Is there a trade-off where depth training hurts or helps the planning objective?
Architecture 6: Vision Transformer Planner (Full Model)
The full architecture: six surround cameras, multiscale TinyViT features, kinematic encoder, and optional auxiliary depth and semantic segmentation heads — all unified under a shared decoder framework.
Key design choices:
- 6 cameras: front, front-left, front-right, rear, rear-left, rear-right
- Shared TinyViT backbone across all cameras (weight sharing)
- Multiscale tokens: 4 levels (56×56, 28×28, 14×14, 7×7) from all cameras
- 3 decoder heads: trajectory, depth, segmentation
- 2D sincos pos enc applied per-camera, 1D sincos for kinematics
- Auxiliary heads detached from trajectory decoder (no gradient leakage)
Ablation questions:
- Does surround-view context (6 cameras vs 1) improve planning?
- Does adding semantic segmentation as an auxiliary task help further?
Chapter 3: Ablation Study Design
The six architectures are not arbitrary — they form a controlled ablation ladder across three independent axes.
Axis 1: Visual Input
| Model | Vision | Cameras | Parameters | Latency (ms) | FPS | Avg L2 (↓) | DS (↑) |
|---|---|---|---|---|---|---|---|
| MLP Planner | None | — | 289K | 0.4 | 2550 | — | — |
| Transformer Planner | None | — | 1.4M | 2.3 | 440 | — | — |
| ResNet-18 Planner (trainable) | ResNet18 | 1 (front) | 20.1M | — | — | 1.800 | 27.6 |
| ResNet Planner | ResNet50 (frozen) | 1 (front) | 33.2M | 7.7 | 130 | — | — |
| Front Cam Planner | TinyViT (frozen) | 1 (front) | 29.6M | 8.8 | 113 | — | — |
| FrontCam+Depth Planner | TinyViT (frozen) | 1 (front) | 35.7M | 11.9 | 84 | — | — |
| ViT Planner (full) | TinyViT (frozen) | 6 (surround) | 41.8M | 66.3 | 15 | — | — |
| ThinkTwice (SOTA) | — | — | — | — | — | 0.95 | ~75 |
Avg L2: mean L2 distance (meters) between predicted and ground-truth waypoints on the Bench2Drive validation split. Lower is better. SOTA is 0.95m from ThinkTwice. DS: mean Driving Score on 10-route closed-loop benchmark (see Blog 5). Results populated as training completes. Latency measured at batch size 1 on an RTX 3090 (fp32); Bench2Drive runs at 10 Hz so ≥10 FPS is required for real-time inference.
Controls: does vision help planning? Does more coverage (surround vs front only) help?
Axis 2: Backbone Architecture
| Backbone | Type | Parameters | Frozen? |
|---|---|---|---|
| None (MLP/Transformer) | — | — | — |
| ResNet50 | CNN | ~25M | Yes |
| TinyViT | ViT | ~28M | Yes |
Control: CNN features vs. attention-based features — which provides better planning cues?
Axis 3: Auxiliary Supervision
| Model | Depth Head | Segmentation Head |
|---|---|---|
| Front Cam Planner | No | No |
| FrontCam+Depth Planner | Yes | No |
| ViT Planner (full) | Yes | Yes |
Control: does geometric/semantic auxiliary supervision act as a regularizer that improves trajectory prediction?
Metrics
All models are evaluated on the Bench2Drive validation split using:
- L2 displacement error at 1s, 2s, 3s, 5s horizons (meters)
- Final Displacement Error (FDE) at 5s horizon
- Collision rate (% of rollouts with ego-obstacle contact, when available)
Auxiliary task metrics (depth AbsRel, segmentation weighted IoU) are tracked separately to monitor auxiliary head quality and its correlation with trajectory performance.
Hypotheses
- Vision helps — even a single front camera should give meaningful improvement over kinematics-only planners, especially in intersection and lane-change scenarios.
- TinyViT > ResNet50 for this task — attention-based spatial features should encode scene geometry better than convolutional features.
- Depth auxiliary supervision helps — geometric supervision should force the shared tokens to encode 3D structure, improving obstacle avoidance.
- Surround cameras help at longer horizons — at 1s horizon, forward camera may be enough; at 5s, knowing what’s behind and to the side matters.
- Segmentation auxiliary has diminishing returns — semantic labels are noisier than depth for trajectory tasks; this one we’re less sure about.
Chapter 4: Early Closed-Loop Benchmark Results
The ResNet-18 planner (trainable backbone, 20.1M params) is the first architecture to reach a deployable checkpoint. It was benchmarked on 10 routes in CARLA via the Bench2Drive leaderboard evaluator at epoch 17 (val avg L2 = 1.800 m). Full methodology in Blog 5.
| Scene | Status | DS | Route% | Penalty | ColVeh | Blocked | MinSpd |
|---|---|---|---|---|---|---|---|
| HazardAtSideLane | ✅ Completed | 60.0 | 100% | 0.60 | 1 | 0 | 21 |
| EnterActorFlow | ✅ Completed | 36.0 | 100% | 0.36 | 2 | 0 | 17 |
| VehicleTurningRoute | ❌ Deviated | 56.2 | 56% | 1.00 | 0 | 0 | 10 |
| NonSignalizedJunctionLeftTurn | ❌ Deviated | 50.8 | 52% | 0.97 | 0 | 0 | 9 |
| SignalizedJunctionRightTurn | ❌ Timeout | 19.1 | 49% | 0.39 | 1 | 0 | 9 |
| OppositeVehicleTakingPriority | ❌ Timeout | 18.4 | 18% | 1.00 | 0 | 0 | 3 |
| HardBreakRoute | ❌ Blocked | 18.8 | 41% | 0.46 | 1 | 1 | 6 |
| ParkingCutIn | ❌ Blocked | 6.9 | 27% | 0.25 | 1 | 1 | 5 |
| AccidentTwoWays | ❌ Timeout | 4.5 | 32% | 0.14 | 3 | 0 | 6 |
| VehicleTurningRoutePedestrian | ❌ Timeout | 5.3 | 43% | 0.12 | 2 | 0 | 8 |
| MEAN | 2/10 completed | 27.6 | 52% | 0.53 | 1.1 | 0.2 | 9.4 |
DS = Route% × Penalty, where Penalty starts at 1.0 and is multiplied down by each infraction (vehicle collision ×0.60, static collision ×0.65, red light ×0.70, etc.). MinSpd is logged but currently not penalising the score. See Blog 5 — Benchmark Metrics Explained for the full breakdown.
Observations at epoch 17:
- No pedestrian or red light violations across all 10 routes — the model is cautious
- The two completions (HazardAtSideLane, EnterActorFlow) suggest the model handles flow-following scenarios well
- TickRuntime failures indicate the agent is too slow per step on compute-heavy scenarios — an infrastructure issue, not a driving quality issue
- Min speed infractions are universal (avg 9.4/route) and confirm the model drives at ~3 m/s vs traffic at 6–8 m/s; currently not penalising score
- Remaining architectures will be benchmarked as training completes
Chapter 5: What’s Next
With the architectures designed and the ablation storyboarded, the next steps are:
- Train all six models to convergence under identical hyperparameters
- Evaluate on the validation set across all displacement horizons
- Visualize planned trajectories on held-out scenarios — especially failure cases
- Quantify the contribution of each ablation axis in an aggregated table
The goal is not just a best-performing model, but a clear understanding of which components earn their compute.
Follow along with the code:
